

.jpg)
If you’ve ever run an A/B test on your website and wondered, “Is this result real or just a fluke?”, then you’ve bumped into the concept of statistical significance. For marketers, growth teams, and CRO professionals, statistical significance is the key to separating meaningful improvements from random noise in your data. In plain English, it’s what tells you whether Version B really beat Version A, or if it only seems better because of chance. In this guide, we’ll demystify statistical significance without the technical jargon. You’ll learn how it applies to A/B testing, what confidence levels and p-values mean in practical terms, and how to know when your test result is truly trustworthy. We’ll also sprinkle in real-world examples (like testing call-to-action buttons) to make things concrete. By the end, you’ll not only understand why statistical significance matters, but also how modern tools (including a brief intro to an AI solution called ezbot) are making it easier to get reliable results.
What is Statistical Significance?
Statistical significance is basically an indicator of confidence that an observed difference is not just due to chance. When you compare two versions of a webpage (say a control version A and a variation version B), you’ll see some difference in outcomes (like conversion rates) between them. The big question is: is that difference real or just random variation? Statistical significance helps answer that.
One expert definition puts it this way: it’s a measure of how unusual your results would be if there were actually no difference at all between A and B. In other words, we assume the null hypothesis – that A and B perform the same – and then ask: “What are the odds of seeing a difference this big just by random chance?”. If those odds are very low, we call the result statistically significant.
To make this less abstract, imagine flipping a fair coin 10 times. You expect about 5 heads and 5 tails. If you got 7 heads, it could happen randomly, but it’s a bit unusual. If you got 10 heads, that’s very unlikely by chance – you’d suspect the coin might be biased. Similarly, in A/B testing, statistical significance quantifies how unlikely your observed difference is under the assumption that your two versions are actually the same. If it’s very unlikely (according to a threshold you set), you conclude the difference is real.
In simpler terms, statistical significance = how confident you can be that Version A vs Version B truly made a difference, not just luck. If a result is not statistically significant, there’s a good chance your “winner” is not a real winner at all. In fact, an insignificant result carries a higher risk that any apparent improvement is just a random blip (a false positive alarm).
Why Statistical Significance Matters in A/B Testing
In website optimization, A/B tests help you make decisions based on data rather than gut feeling. But data always have some randomness. If we ignore statistical significance, we might pick a “winning” webpage variant that isn’t actually better – simply because a lucky streak of users made it look good. Achieving statistical significance gives us confidence that our test conclusion (like “Version B’s new headline does increase sign-ups”) is reliable and not due to random fluctuations.
This is crucial because in practice most A/B tests don’t yield dramatic wins. In fact, studies have found that anywhere from 50% to 80% of tests end up inconclusive, and only about 1 in 7 tests shows a clear winning result. That means you’ll often run tests where differences are small or uncertain. Statistical significance is the guiding light to tell you when an outcome is solid enough to act on. It helps you distinguish between a real improvement and the random ups and downs inherent in visitor behavior. Without it, you might chase mirages – implementing changes that don’t actually help (or worse, hurt your metrics).
Example: Testing Two Call-to-Action Buttons
Let’s bring this to life with a simple example. Suppose you’re testing two versions of a call-to-action (CTA) button on your homepage:
• Version A (Control): Blue button with text “Sign Up Now”
• Version B (Variation): Green button with text “Join Us Free”
You run an A/B test splitting traffic between A and B. After a few days, you see the following results:
• Version A: 100 conversions out of 2,000 visitors (5% conversion rate)
• Version B: 120 conversions out of 2,000 visitors (6% conversion rate)
At first glance, Version B is doing better (6% vs 5% conversion rate). That’s a 20% relative lift. Great news, right? 🤩 But before declaring B the winner and rolling it out to everyone, you check the statistical significance. The testing tool reports a 95% confidence level for B’s improvement, which typically corresponds to a p-value of 0.05 or below. This means there is at most a 5% probability that seeing this big of a difference was purely due to chance. In practical terms, you’re ~95% sure B’s green button is indeed better than A’s blue button.
If instead the test showed a lower confidence level, say 80% (p ≈ 0.20), it would mean a 20% chance the observed difference is just luck – much too high to trust. You’d likely call the result inconclusive and not switch all your buttons to green based on that test alone. By requiring statistical significance (usually 95% confidence), you ensure that when you do make a change, it’s backed by strong evidence and you’re not gambling with your conversion rate.
Confidence Levels and P-Values: What Do They Mean?
Two terms you’ll often hear with statistical significance are p-value and confidence level. They sound technical, but the concepts are straightforward when explained in plain language:
• P-Value: This is a number (between 0 and 1) that comes out of a statistical test. It represents the probability of observing an effect as extreme as (or more extreme than) your test result if there really was no difference between your variants. A small p-value indicates that your result would be very unlikely if A and B were truly the same. For example, a p-value of 0.03 means there’s only a 3% chance that the difference you saw is due to random chance. That’s pretty strong evidence that the change in B had a real effect. On the other hand, a p-value of 0.5 would mean a 50% chance the difference is just random noise – basically no confidence at all in a real difference.
• Confidence Level: This is essentially the flip side of the p-value. It’s usually expressed as a percentage, and it indicates how sure you want to be before calling a result significant. The confidence level plus the significance threshold add up to 100%. So a common choice is 95% confidence level, which corresponds to allowing a 5% chance of error (since 100% – 95% = 5%). In practice, saying “We used a 95% confidence level” means “We require that the p-value be 0.05 or less to consider the result real.” If you use a 90% confidence level, you’re being a bit more lenient (accepting a 10% chance of being wrong to call a winner). If you use 99%, you’re being very strict (only a 1% chance of a fluke is acceptable). Most teams default to 95% as a balance between confidence and speed. In other words, you’re saying “I’m okay with a 5% risk that this result is just a fluke, and 95% confident it’s real.”
It’s important to note that statistical significance isn’t a 100% guarantee – it’s about probability and risk. A 95% confidence level (p < 0.05) means there’s still a 5% chance you could be seeing a false positive. As the team at Eppo explains, even if you pass the magic 0.05 threshold, it “doesn’t confirm that the alternative hypothesis is true” with absolute certainty . It simply means you have enough evidence to reject the assumption of “no difference”. Conversely, if you don’t reach significance, it doesn’t prove your new version has no effect; it might just mean you need more data or the effect was too small to detect (this is called a Type II error, or a false negative) .
The key takeaway: p-values and confidence levels are tools to quantify uncertainty. They help you decide, “Am I confident enough in this result to take action?” A low p-value (combined with a high confidence level) gives you the green light to consider the result trustworthy. A high p-value (low confidence) is a yellow or red light – be cautious, you likely need to keep testing.
Knowing When to Trust Your A/B Test Results
How do you know when a test result is truly trustworthy and ready to be acted upon? Reaching a desired confidence level (like 95%) is one big requirement, but there are a few other practical guidelines to ensure your A/B test result is solid:
• Run the Test for Sufficient Time: Don’t rush to judgment. It’s recommended to run a test for at least one full business cycle (typically 7 days) to account for day-of-week patterns. For example, if you start a test on Wednesday and stop it by Friday, you might miss weekend behavior or Monday blues. Running at least a week helps smooth out these variations. In fact, Optimizely’s best practices suggest running until you reach significance or for at least 7 days, whichever is longer.
• Ensure Adequate Sample Size: Statistical significance is closely tied to sample size – too few visitors and your test may never reach a trustworthy conclusion. Before you start, estimate how many visitors or conversions you need to detect a meaningful difference (many A/B testing tools or calculators can help with this). If you stop when only a tiny fraction of that sample has been collected, the result is unreliable. Small sample = high uncertainty. A good rule of thumb is to plan the test duration such that you can collect the needed sample for your expected lift. If you end up with an “underpowered” test, even a real difference might not show up as significant.
• Don’t Peek or Stop Early: It’s tempting to look at your A/B test dashboard every day and see if a winner emerges. But be careful – checking too frequently or ending a test the moment you see 95% could mislead you. Early on, the metrics can oscillate between significance and non-significance as data trickles in.
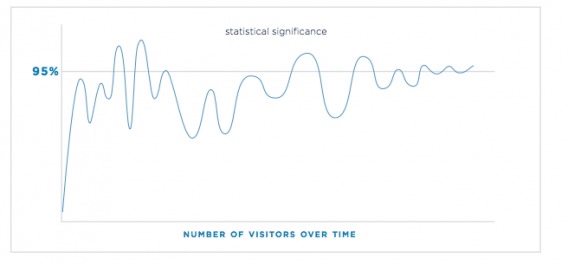
You can see how a test’s significance level (y-axis) can fluctuate above and below the 95% line as more visitors participate (x-axis). In the beginning, the line jumps around – it might even cross 95% briefly – but that doesn’t mean the test has truly proven a winner yet. If you stopped at one of those early spikes, you might call a false victory. That’s why experts caution that statistical significance should not be used as a premature stopping rule. It’s best to decide beforehand how long to run the test or how many visitors to gather, and stick to that plan. By waiting until the data stabilizes, you avoid the trap of chasing random fluctuations (a problem known as “peeking” or alpha error inflation when you check too often).
• Focus on One Primary Metric (and Limit Variations): Every additional thing you measure or extra version you test increases the chances of a random significant result. If you test many variations at once or look at too many metrics, you’re more likely to find a “lucky” significant difference somewhere (this is sometimes called p-hacking). It’s okay to track secondary metrics, but have a clear primary success metric for each test (e.g., click-through rate or purchase conversion) and base your main conclusion on that. Similarly, testing two versions (A and B) keeps the analysis straightforward; if you test A vs B vs C simultaneously, you need to adjust for the fact you had multiple comparisons (which is more complex). For a non-technical team, sticking to simple A/B with one key metric makes it easier to trust the result.
• Consider Practical Significance: Statistical significance only tells you that a difference is likely real, not how big or important that difference is. Especially with large sample sizes, a very tiny improvement can show up as statistically significant. Always ask, “Is this difference large enough to matter for our business?” . For instance, if Variant B is statistically significantly better by +0.1% in conversion rate, that might not justify a redesign if it’s a trivial impact on revenue. So before celebrating, ensure the lift is meaningful in practical terms (sometimes called practical significance).
By following these guidelines, you’ll greatly increase your chances that when you do call a winner, it’s the real deal. And don’t be discouraged by inconclusive results – as noted, the majority of tests in mature programs are inconclusive. An inconclusive result can still provide learnings (e.g., that a certain change didn’t hurt metrics, or that you need a bigger change to move the needle). The goal is to learn and iterate with confidence that when something does shine as a winner, you can trust it.
Conclusion: A Smarter Way to Test – Meet ezbot
Understanding statistical significance empowers you to run A/B tests responsibly and make data-backed decisions. You’ve seen that it involves some careful planning and patience – crunching numbers, monitoring p-values, and waiting for that 95% confidence. But what if this could be made easier? In recent years, modern AI-driven tools have emerged to simplify experimentation. One such solution is ezbot, an AI-powered optimization platform designed to take the heavy statistical lifting off your shoulders.
Instead of manually calculating p-values or constantly checking if you’ve hit significance, ezbot uses AI to automate the A/B testing process. In fact, it goes beyond traditional A/B testing into something more dynamic. How does it work? ezbot’s AI continuously tries out different content or design variations on your site and learns from every visitor interaction. Over time (and often much faster than a manual test), it identifies which variant is performing best and starts showing that winner more often – automatically. It’s like putting your website optimization on autopilot: the high-performing experiences get delivered to more users without you lifting a finger.
The benefits are pretty exciting for non-technical teams: you don’t have to manually compute statistical significance or even wait until a fixed test period ends. The AI is effectively doing an ongoing experiment and optimization in the background. This means you get faster results and can respond quickly to what works. And because it’s AI-driven, it can even explore combinations of changes (multivariate) that would be hard to A/B test one by one. All the while, built-in algorithms ensure it’s not jumping to conclusions without enough evidence – in other words, it’s handling the statistical rigor for you.
In summary, statistical significance remains a fundamental concept for trustworthy A/B testing. For those improving websites, it’s the compass that tells you when a test result is real. By understanding p-values and confidence levels, and following best practices, you can run experiments that genuinely move the needle. And as tools like ezbot show, the future is making this process more automated and intelligent. That means you can spend less time number-crunching and more time coming up with great ideas to test – a win-win for you and your conversion rates.
Happy testing!
👉 Check out our post on how conversion rate optimization is changing for non-technical teams.






